
Agent (Google,2024)读后感
本篇文章为 2024 年 Google 团队发布的一份白皮书的读后感,原文作者为 Julia Wiesinger, Patrick Marlowand, Vladimir Vuskovic,链接为Google Agent White Paper 2024
构成
Agent 主要由 3 部分构成,一是底座模型,也就是基础的 LM,二是编排架构,Agent 实现的核心层,三是工具层,使模型能够获取实时信息以及和现实世界交互。 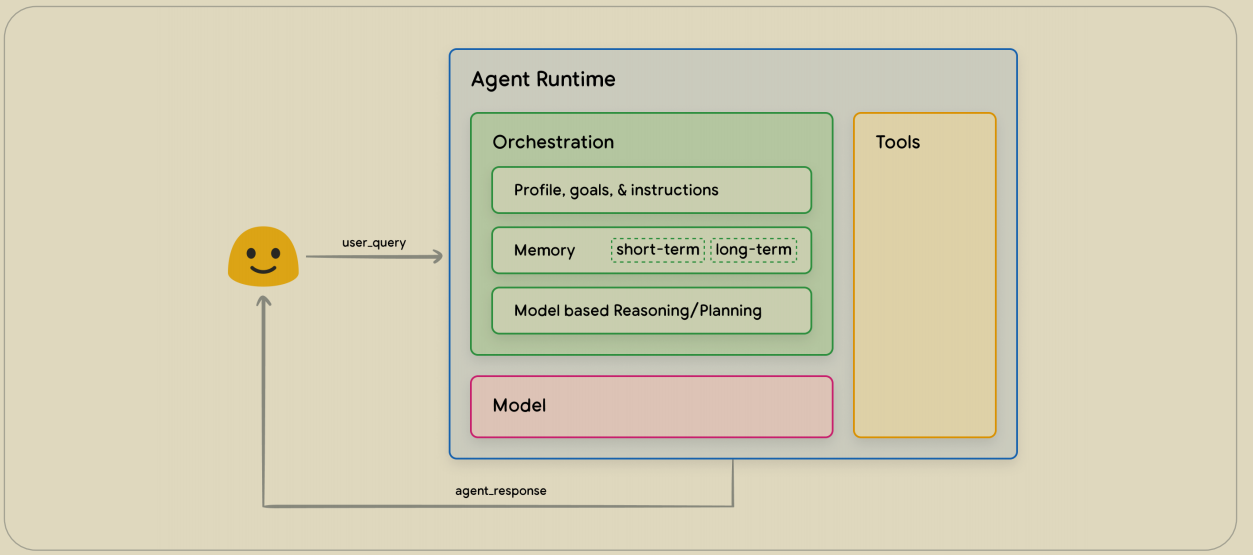
编排架构
相较于直接对 LM 发出询问,LLM 直接生成响应的模式不同,Agent 在得到用户的 query 后并不会直接将 LLM 的结果返回,因为对于用户当前的问题并不一定有足够的能力直接回答。 Agent 的核心能力与编排架构层直接相关,简单来讲这是一个描述模型如何周期性的去获取足够信息的架构。 例如典型的 ReAct 框架中,将周期分为了推理(reasoning)和行动(acting),通过提示词提供的样例模板使模型知道它能够以何种方式调用「Tools」以获取更多的实时信息或与外界进行交互。 基于此,编排的作用是为了引导模型以一个可循环的模式进行行动,例如在开始时需要判断当前的信息是否足以回答用户的问题?可以调用的这些工具是否需要使用?(思考)随后又模型进行决策,若需要调用工具则以个定格式进行输出(行动),调用的结果将在下一次循环中作为信息的补充(观察);若不需要进行工具调用,则直接基于当前信息进行响应。 对于单个 Agent 有这普通的周期模式,对于更垂类的场景还可以进一步引导出「状态机」的模式,系统可以由多个 Agent 组成,将任务分解为多个状态,于不同状态中由不同的 Agent 进行负责,例如在规格化的文章任务中,Agent1 负责处于撰写或修改状态的任务,而 Agent2 负责处于待审阅状态的任务,Agent2 将会对当前文章的内容和格式进行检查,若检查通过则是任务进入下一阶段,若未通过则给出修改意见,使任务流转回修改状态。
Tools
Function Calling
各个模型厂商最初为了扩展 LLM 获取实时信息的方式,由 LLM 自行基于上下文进行意图识别,并选择需要的工具获取信息。 Function Calling 基于编程中 function 的思想,传入特定参数,获取响应,而其具体的实现也是将 Json 反序列化获取参数,执行响应的代码。局限性主要有两点:
- 与 Agent 应用深度绑定,具体的行为需要在当前应用中提前设定好,无法动态发现
- 难以复用,同样的方法功能,如果要在另一个 Agent 应用上使用需要进行移植,无法直接复用
MCP
虽然文章中没有提到(毕竟是 2024 年的文章),但站在现在的角度,MCP 理应作为 Tools 的一种方式 模型上下文协议(Model Context Protocol),在 Function Calling 的基础上提供更高级的工具集成, 作为统一的开源协议,省去了 Function Calling 百家争鸣带来的适配复杂度。其次 MCP 的重心在于一个相对独立的 Server,通过访问 MCP Server 可以动态获取可调用的工具集,并且不同的 Agent 应用可以访问同一个 MCP Server,提高可复用性。 MCP Server 虽然解决了 Function Calling 的痛点,但也带来了服务中心化带来的服务部署和维护成本。
总结与思考
Agent 的构成并不复杂,相较于直接响应的形式 Agent 最大的特点是能够借助 Tools 实时获取到模型训练知识数据之外的数据,并将其作用于改善当前的回答。 对于一些多 Agent 的编排,可以针对垂类场景进行任务状态的优化,但基于 transformer 架构的 LLM,其生成的结果始终是基于概率的,即便多 Agent 可以设置检查校验的机制,受限于 LLM 能力以及状态流转的深度(不可能无限循环于此),一个系统永远都能生成符合要求的结果并不现实,因此并不适合直接替代传统流水线等对输出结果的稳定性强要求的场景。